
新智元报道
编辑:艾伦 定慧
【新智元导读】 Llama4性能造假丑闻,OpenAI烧钱的速度远超过了盈利能力;另外一方面:国产模型凭借足够强大的性能与超高性价比,迅速占领了国际开源模型市场。是时候再次为国产AI鼓掌了!
今年,全球AI界见证了两座「灯塔」的同时动摇。
首先是开源世界的灯塔轰然倒塌。
Meta的Llama 4被曝出评测性能造假,这场令人大跌眼镜的丑闻,让其耗费巨资打造的开源领导者形象蒙上了一层难以洗刷的阴影。
Llama 3.1成为Meta引领开源模型的最后荣光,Llama 4的模型排名甚至不如Llama 3.1。
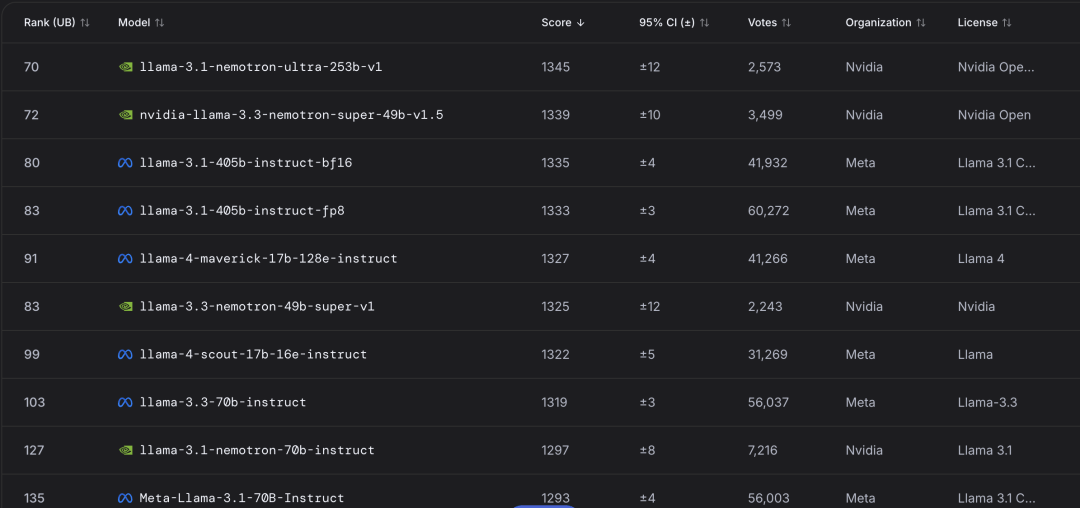
LMArena排行榜最新数据
丑闻爆出后,小扎如坐针毡,颜面尽失,立即着手开启了大刀阔斧的改革,发起了一系列声势浩大的挖角大行动,用上亿美元的高薪不断从OpenAI等竞争对手挖来顶尖AI人才,试图用钱来砸出一个能让Meta一雪前耻的最强大的Llama 5。

紧接着,闭源世界的灯塔也开始摇晃。
OpenAI的CFO竟公开寻求美国政府为其高达1.4万亿美元的算力计划「兜底」,此言一出,市场恐慌。美国科技股一夜应声蒸发5000亿美元,华尔街用脚投票,表达了对这个万亿估值泡沫的深切忧虑。
一个严峻的现实摆在了全世界面前:全球AI的发展,正陷入一个巨大的「真空地带」。
海外开源的模型被证明不可靠,而顶尖的闭源模型又昂贵得像一场看不到尽头的豪赌。
市场需要一股新的力量——既要性能强大,又要价格实惠,更要商业上可持续。
中国的AI力量,恰如其分地在国际舞台迅速爆发,满足全世界的刚需。
这些强大的国产开源模型甚至得到了国外AI圈的盛赞:「是中国拯救了开源模型!」(China saved open-source LLMs)

当全球开发者们在Llama 4的废墟上失望地寻找下一个「救星」时,他们看到了DeepSeek、MiniMax、Kimi、智谱这些冉冉升起的中国旗帜。
这并非偶然的后来居上,而是一场更务实的、用中国效率来填补全球需求真空的行动。
中国AI的全球渗透
面对全球市场的真空,中国AI的答案并非单一维度的猛攻,而是全方位、多模态的围剿。
首先,DeepSeek的爆火,让全球看到了AI原来可以成为如水电般的「基础设施」。
DeepSeek专注于「推理优先」的文本核心能力,通过极致的开源和极低的价格,让全球开发者都能「随处可得」——借助Azure、GitHub等全球分发渠道,与企业主流工作流无缝对接,迅速成为开发者社区中一个绕不开的「标准」。
DeepSeek的目标,后来也成功做到了,就是让AI的准入门槛降低。

DeepSeek研究成果登上《Nature》封面
如DeepSeek拓宽了AI应用的广度,MiniMax的技术积累和商业布局同样亮眼。
相比于DeepSeek、Kimi和智谱,MiniMax代表了另一条路径——多模态同时发力。
在多模态模型研发方面,MiniMax自主研发了语音、视频和音乐模型,并在今年六月与十月的技术发布周中展示了相关成果。
其视频生成模型被海外创作者用于制作「猫跳水」等短视频,在全球社交平台上获得了超过3亿次观看,催生了以动物角色为主角的「动物奥运会」等AI视频创作趋势。
10月底发布的M2,在OpenRouter这个全球最大的模型聚合平台上的成绩,则证明了其在文本模态上的实力。
从日调用量的增速来看,自发布以来增长迅速。
免费期间,Token日调用量达到50B,开通Coding Plan付费之后,付费日调用量也很快增至50B。

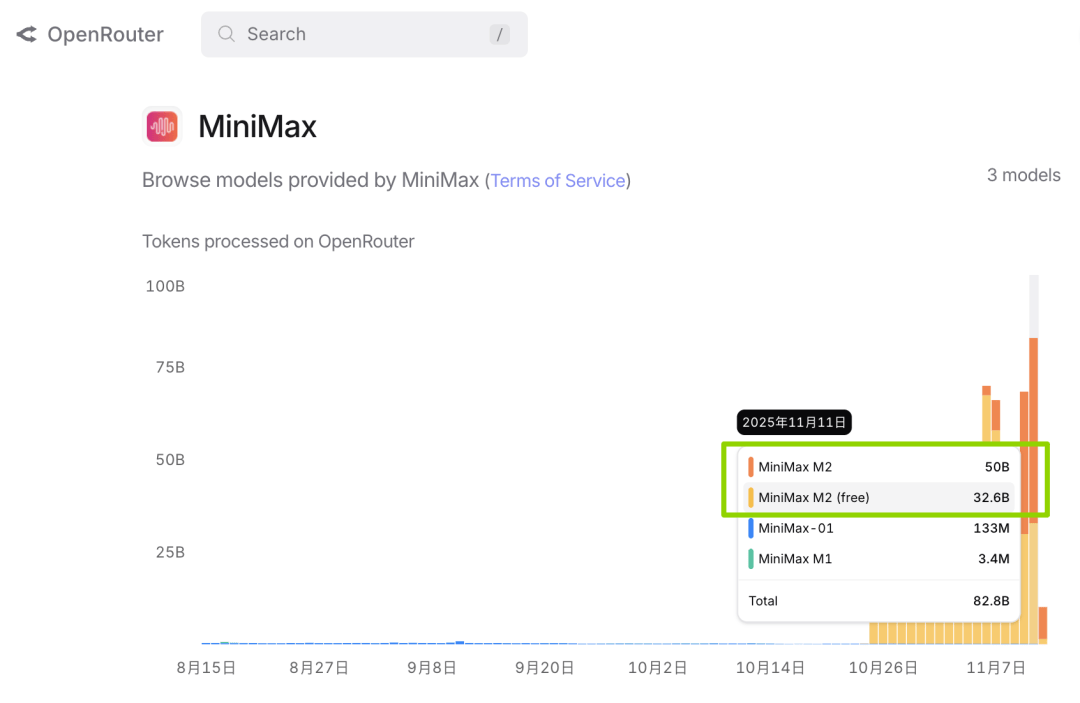
足够强大的性能,加上极致的性价比。
M2将价格压至海外同级别模型的10%以下,也成为了全球企业和开发者工具箱中的首选的「工程刀」。
以DeepSeek和MiniMax为代表的中国AI,形成了一股强大的合力。
前者负责把使用门槛降到地板,而后者进一步把优势范围扩大,让中国模型在全球范围内,从「备选项」强势崛起为「必选项」。
拒绝「烧钱」的极致效率
成为「必选项」的前提,需要建立在两个坚实的基础之上:极致的效率和健康的商业闭环。
这正是中国模式与硅谷「烧钱」模式的根本区别。
与DeepSeek专注技术研发的另一个不同之处在于,MiniMax在技术布局的同时,也在进行产品布局。
建立在极具性价比的技术之上,产品能够进一步放大这种优势。
「花小钱,办大事」是中国AI效率的代名词。
在算力客观受限的环境下,中国工程师们爆发出了惊人的算法创新潜力。
DeepSeek以低成本高性能闻名,其研究成果登上《Nature》封面,为中国开源模型的「低成本传说」赢得了国际权威的认可。
而MiniMax的效率同样令人难以置信:6月发布的MiniMax M1模型,强化学习阶段仅用512块H800训练三周,租赁成本仅54万美元,训练成本不足OpenAI同类模型的1%。

这种极致的成本控制,直接转化为价格优势;体现在产业侧的,就是「单位智能成本」。
MiniMax M2仅有230B总参数和10B激活量,仅用海外模型三分之一的参数量,实现了更好的智能效果和更高的性价比,在最复杂的编程场景可用,好用。
当M2的价格仅为性能相近的Claude Sonnet 4.5的8%,这种极致的性价比本身,就是一种足以颠覆全球市场格局的、最强大的「武器」。

海外科技媒体《The Information》报道
能持续留在牌桌上,还需要健康的「自我造血」能力。
在这方面,中国AI走出了更为清晰的路径。
DeepSeek实现了从技术打入社区,以及企业部署服务的基础设施路线,通过免费和极低价的开源模式,为全球企业提供API,助力项目落地实现商业化。
MiniMax在B端和C端构建了「模型—产品—收入」的闭环。
MiniMax自研的多模型均做到了全球领先,且可以以产品化的形式来直接服务用户,通过To C应用Talkie、海螺AI、MiniMax Agent等,将模型能力高效转化为现金流,再反哺更大规模的模型训练。
OpenAI与MiniMax类似,在商业模式上同样选择「模型+产品」的打法,但在模型迭代上极度依赖外部巨额输血,可持续性需要打一个问号,而能否自我输血,才是AI企业的下一个决胜点。
AI本身不是泡沫
但AI不能造神
科技的浪潮,终将冲刷掉泡沫,留下真正的价值。
当信仰Scaling Law的硅谷巨头们遭遇万亿资本支出的现实困境时,世界开始重新思考通往AGI的更优路径。
被低估的中国AI用「极致效率」和「商业闭环」,给出了一个全新的答案:通往未来的路,不只有一条烧钱的独木桥,还有一条精打细算、步步为营的阳关道。
正如谷歌曾用开源定义了软件工程的黄金时代,今天的中国力量正在用一种更务实、更普惠的方式,以海外AI企业的「百倍ROI」定义着AI应用的全新纪元。

