| huozm32831 | 2025-05-24 20:10 |
 新智元报道 编辑:KingHZ 【新智元导读】100多天前,DeepSeek-R1凭借低训练成本,名噪一时。而强化学习算法GRPO,是背后最大的功臣之一。然而,开源界对强化学习算法的探索并没有终结。 DeepSeek-R1引爆了LLM推理革命。 DeepSeek-R1的秘籍在于强化学习微调算法:群体相对策略优化(Group Relative Policy Optimization,GRPO)。 未来,LLM的训练将不再是单纯的数据训练,而是将推理能力作为标准流程。 那为什么强化学习能提高LLM的推理能力? DeepSeek-R1的GRPO,有哪些身前身后事? 在后DeepSeek-R1时代,GRPO又引发了哪些奇思妙想? 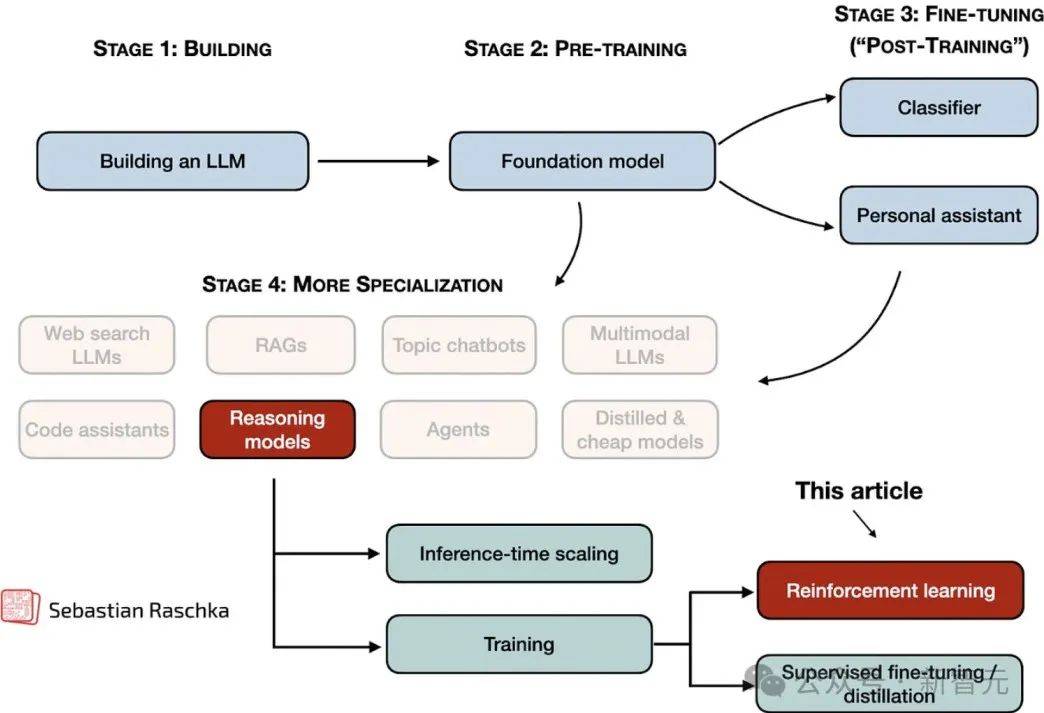 什么是推理模型? 首先要面对的核心问题是:什么是推理? 简单来说,推理是一种通过推导和训练手段,使大语言模型(LLMs)更擅长处理复杂任务的能力。 技术一点的说法是: 推理是指LLM在给出最终答案之前,能先生成一系列中间步骤的能力。 这个过程通常被称为「思维链」(Chain-of-Thought,简称CoT)推理。 在CoT推理中,模型会显式地生成一系列结构化的陈述或计算步骤,来说明它是如何得出结论的。 下图展示了这一定义及其示意。 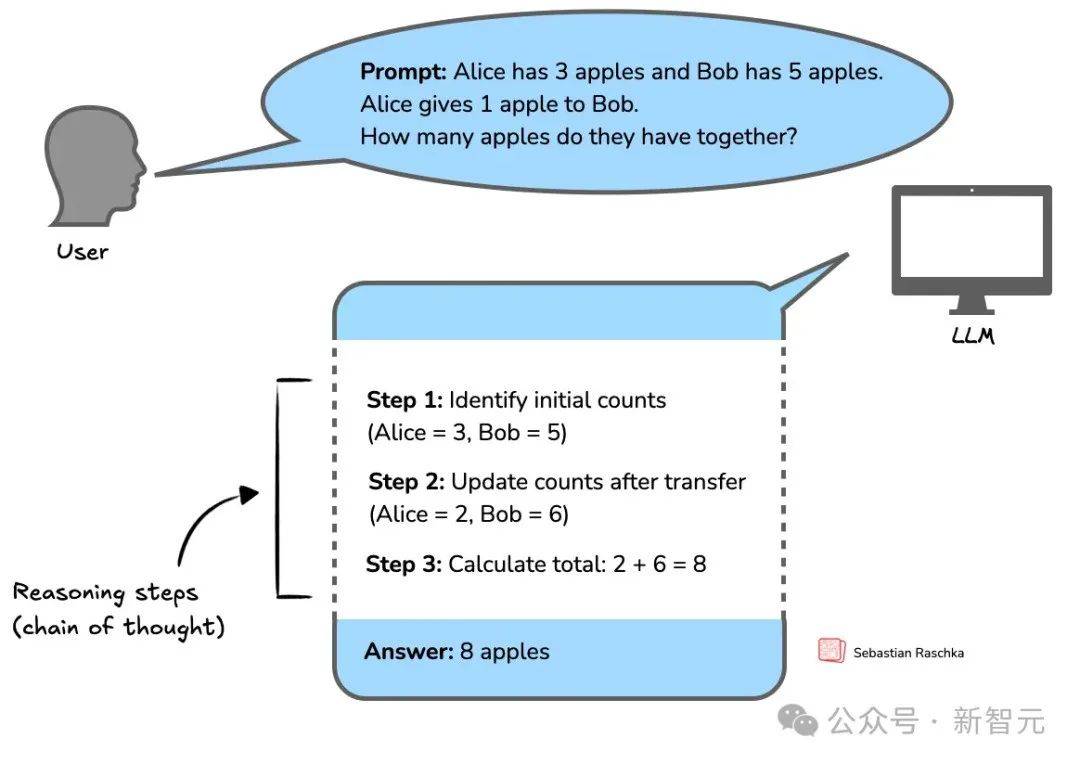 大语言模型(LLM)处理多步骤推理任务示意图 在多步骤推理任务,与直接回忆某个事实不同,推理模型需要结合多个中间推理步骤,才能得出正确的结论。 这些中间推理步骤是否展示给用户,取决于具体的实现方式。 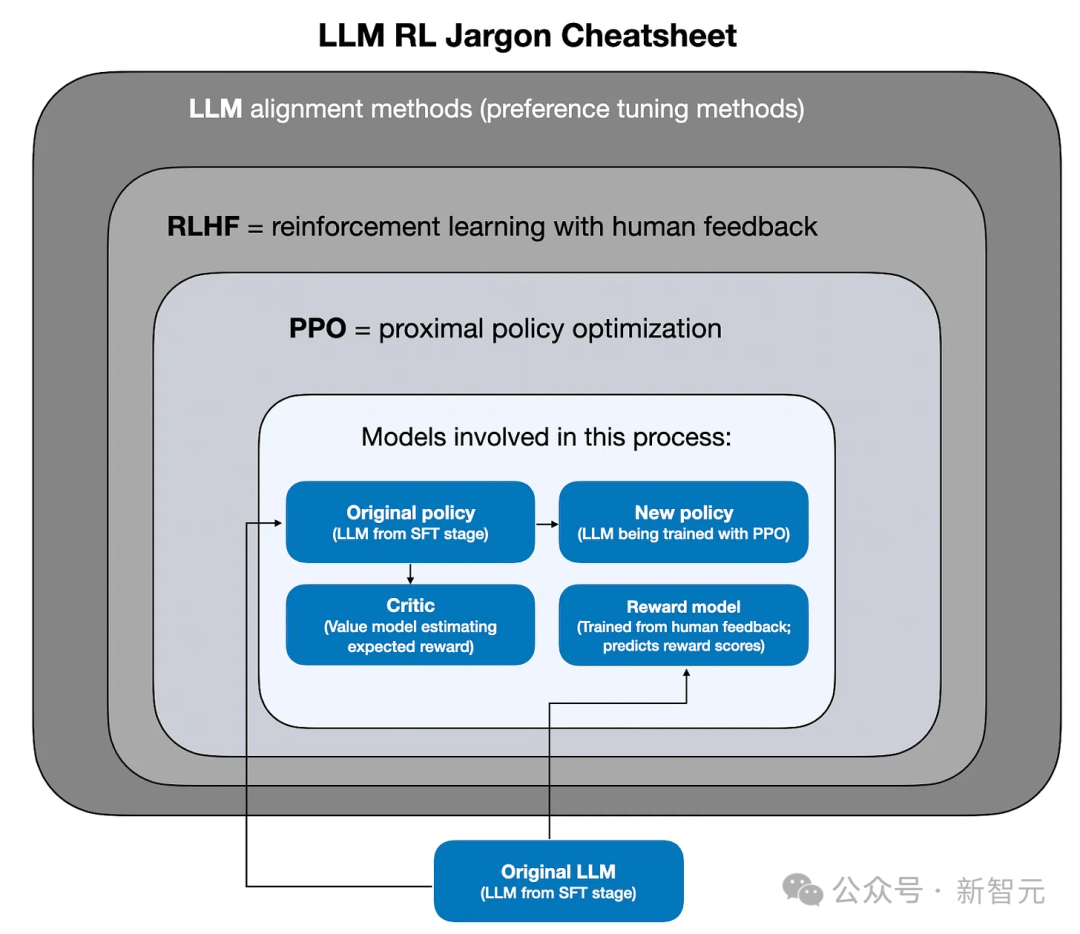 LLM强化学习黑话小抄 RLHF基础:一切的起点 用于构建和优化推理模型的强化学习(RL)训练方法,基本上都与人类反馈强化学习(RLHF)有关—— 这也是目前用来开发和对齐传统大语言模型(LLMs)的主流手段。 因此,在深入讨论基于强化学习的推理优化方法之前,我们先简要回顾一RLHF是如何工作的。 传统LLM的三阶段训练流程: 预训练(Pre-training):使用大规模语料让模型学习通用语言模式和知识。 监督微调(Supervised Fine-tuning):用人工标注的任务数据进一步训练模型,让AI更擅长完成具体任务。 对齐阶段(Alignment,通常通过RLHF):让模型更符合人类偏好,提升交互体验与安全性。 RLHF训练流程会从预训练模型开始,然后通过监督学习进行微调。 这一步还不属于强化学习,而是为后续的RL打下基础的前置步骤。 接下来,RLHF会使用强化学习算法,进一步对LLM进行对齐。 这是本文的重点。 整个RLHF流程分为三大步骤: RLHF第一步(前置步骤):监督微调预训练模型 这一步的目标是通过人工标注的数据对模型进行有监督学习,构建一个适合后续RLHF微调的基础模型 RLHF第二步:构建奖励模型(Reward Model) 收集多个回答并让人类标注哪一个更好,以此训练一个模型,能够根据输出内容给出高或低的「奖励分数」。 RLHF第三步:强化学习微调 使用奖励模型的评分结果作为奖励信号,利用PPO等算法更新语言模型的策略,使其输出更符合人类偏好。 RLHF第一步要创建或从已有数据集中采样一批提示语(prompts),然后由人类标注者为这些提示语编写高质量的参考回答。 接着,我们使用这些人工标注的数据对预训练语言模型进行监督微调(SFT)。 正如前面提到的,这一步并不属于强化学习,而是作为后续RLHF微调的前置准备。 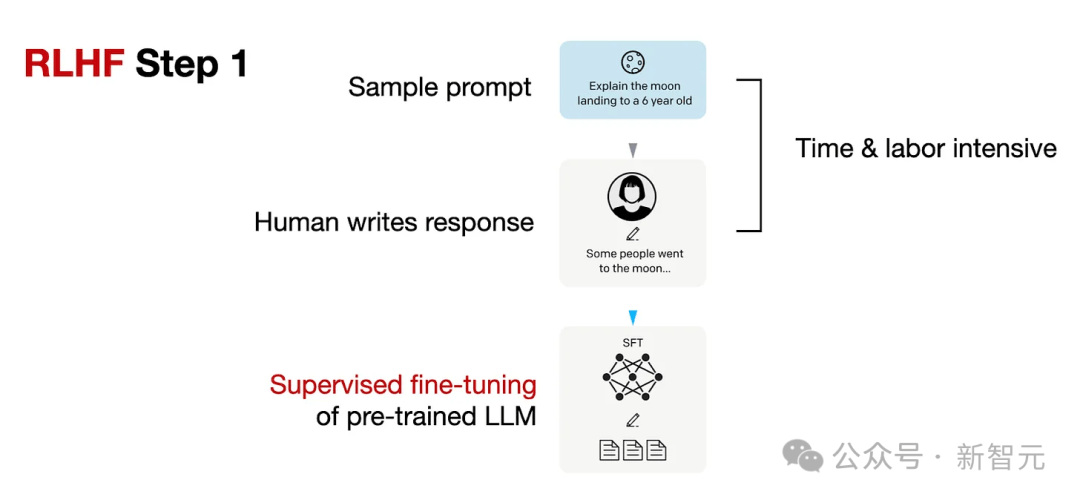 RLHF第二步将第一步微调后的模型用于构建一个奖励模型(Reward Model)。如下图所示: 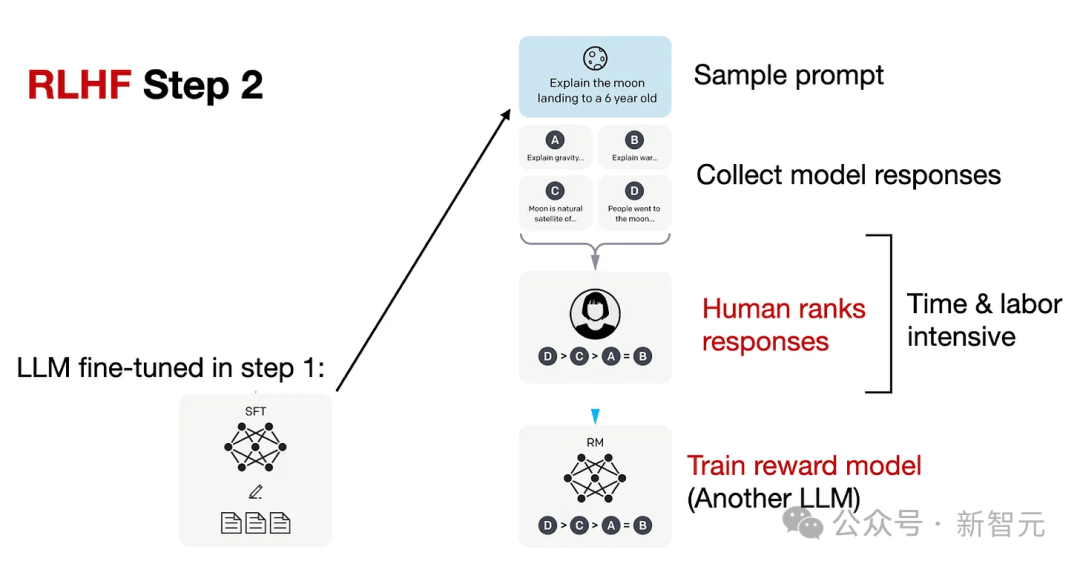 我们让人类对多个模型生成的回答进行排序,然后用这些排序数据来训练奖励模型,让它能根据回答的质量输出相应的评分。 这个奖励模型将在接下来的强化学习微调中,作为模型行为的评估依据。 RLHF第三步(也是最后一步)使用在第二步中训练好的奖励模型,为模型生成的回答打分,然后基于这些评分,使用近端策略优化(PPO)等算法对SFT模型进行强化学习微调。 这是强化学习发挥作用的地方。 通过强化学习,模型会逐步调整其输出策略,使其更倾向于生成高奖励(即更符合人类偏好)的回答,从而实现真正的人类反馈对齐训练。 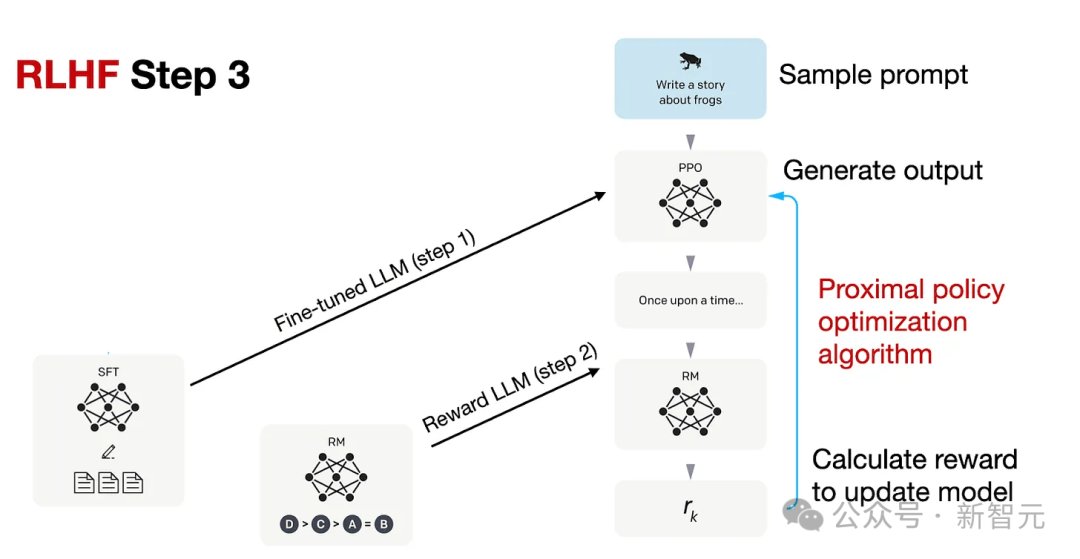 OpenAI的PPO 一开始,RLHF采用的是近端策略优化PPO。  PPO在架构中使用了四个不同的语言模型: 一个 策略模型(正在训练的模型)、 一个 参考模型(原始模型的冻结副本)、 一个 奖励模型(基于人类偏好进行训练) 和一个 值模型(估计长期奖励)。 这些模型都包含需要反向传播来优化的可训练参数,这消耗大量的GPU内存和计算周期,使得训练过程变得笨重且昂贵。 监督学习能够快速定义损失函数,且通常无需大量超参数调整。整个过程直观、稳定、可控。 但在强化学习中,成功的路径就不那么明确了: 强化学习算法往往包含许多相互依赖的模块,调试困难。 而且要想获得良好结果,通常需要投入大量的精力进行调参和结构调整。 这也是PPO被广泛采用的原因之一—— 它在实现简便性、样本效率和调参难度之间取得了较好的平衡。 PPO的核心思想是: 在每一步中计算一次策略更新,既能 最小化代价函数,又能确保新策略与旧策略之间的 偏差不会过大。 OpenAI提出了全新目标函数,增强了PPO算法的稳定性和实用性。 其主要公式如下: 其中: (q,a)是数据分布D中的一个问答对。 πθ表示新策略模型输出的概率。 行为策略πθold表示旧策略模型的输出概率。 πθ/πθold是重要性采样比(importance ratio),主要用于确保新旧模型的分布不会相差太大。 ε是用于裁剪重要性比值的参数,用来限制模型分布的变化,防止变化过大或过小。^A_t是优势函数(advantage function),主要来源于奖励模型和价值模型的评分。 R_l是奖励模型的评分。 V是价值模型的评分。 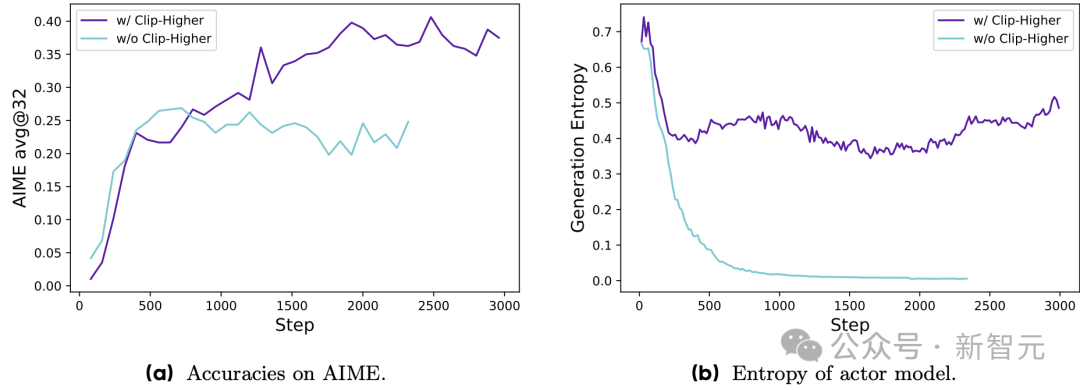 图1:在RL训练过程中,应用Clip-Higher策略前后,AIME测试集上的准确率和演员模型生成概率的熵对比 图1展示了在使用与不使用裁剪参数的情况下,模型在AIME数据集上的表现和生成的熵值对比;可以明显看到,加入裁剪参数后,模型性能和熵值都有显著提升。 DeepSeek的GRPO 传统PPO训练方法往往代价高昂,需要消耗大量GPU计算时数,导致训练成本居高不下,实际应用门槛远超个人开发者和小型研究团队的承受范围。 突破性进展来自DeepSeek。 他们推出了PPO算法的改进「平替版本」GRPO: 在 提升数学推理能力的同时,显著 优化了PPO的内存 使用效率。  DeepSeek-R1训练流程 创新的核心动机在于提升计算效率。 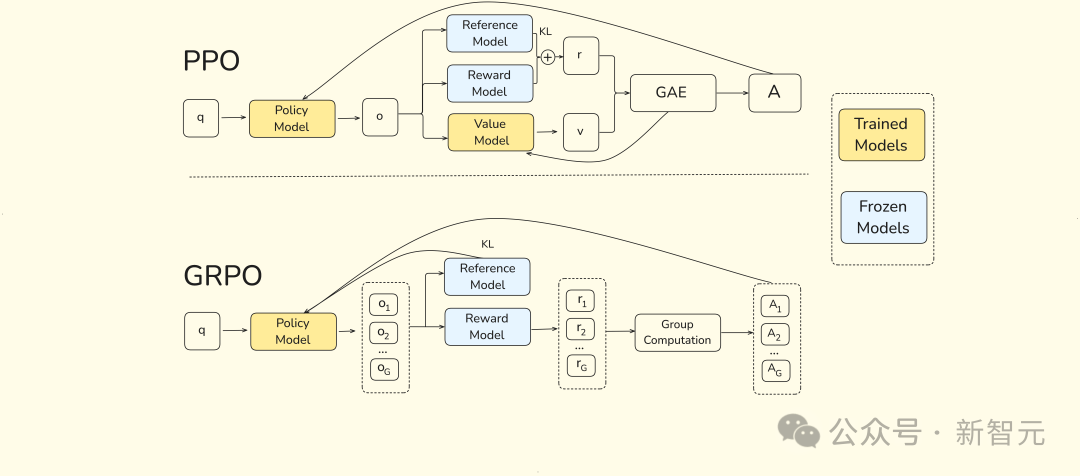 该效率提升主要通过以下方式实现: 剔除「评论家」(价值模型):即传统用于计算价值函数(预期未来收益)的大语言模型组件 采用相对质量评估:通过对策略模型本身生成的多组答案进行质量对比,直接计算优势函数,取代传统依赖额外模型估算奖励的方法 这一创新显著降低了训练推理模型的计算需求,即使是「GPU资源匮乏」的团队,也能开发出复杂的推理能力。 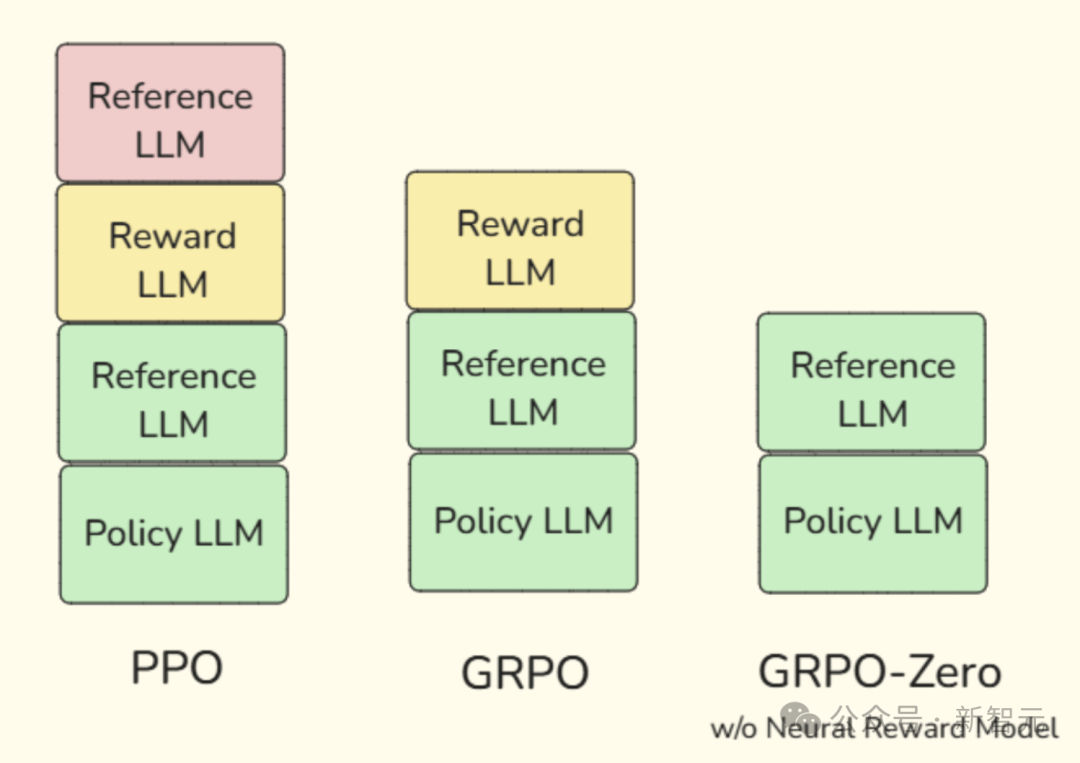 其公式如下: 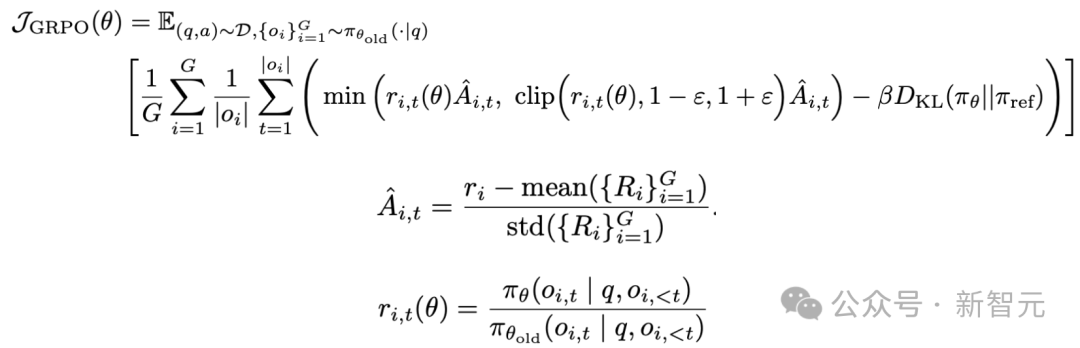 GRPO的主要变化包括: 每个提示语(prompt)采样多次形成一个组,然后使用该组中奖励值的标准化结果作为优势值。 引入KL散度作为正则项,对策略变化加以限制。 由于GRPO主要用于数学或逻辑推理类问题,它使用的奖励模型也是基于规则的。例如: 其中,y是标准答案,y^是预测 答案。 GRPO的开源升级版:DAPO 然而,当前顶尖推理型大模型的关键技术细节(如OpenAI的o1技术博客和DeepSeek-R1技术报告中的内容)仍处于黑箱状态,导致学术界难以复现他们强化学习训练成果。 于是,开源的解耦裁剪与动态采样策略优化(Decoupled Clip and Dynamic sAmpling Policy Optimization,DAPO)问世了。 DAPO为每个与答案a配对的问题q采样一组输,并通过以下目标函数优化策略: 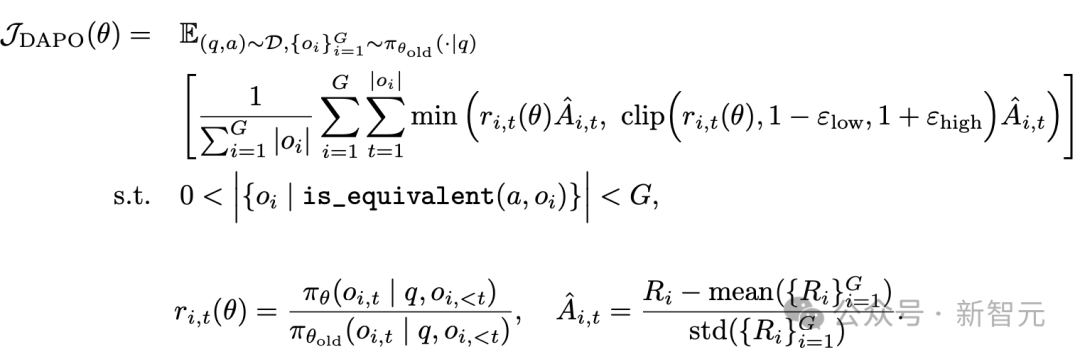 DAPO包含以下几个关键技术点: Clip-Higher(高限裁剪):提升系统多样性,避免熵崩溃。在策略梯度损失中提高重要性采样比率(importance sampling ratio)的上裁剪限值,以缓解该问题。 Dynamic Sampling(动态采样):提升训练效率与稳定性。动态采样策略可以过滤掉准确率为1或0的提示组(prompt groups),并在各批次中保持有效梯度提示的数量一致。 Token-level Policy Gradient Loss(Token级策略梯度损失):在长链思维推理(long-CoT)强化学习场景中至关重要。 Overlong Reward Shaping(过长奖励重塑):降低奖励噪声,稳定训练过程。 高限裁剪 从前面的公式可以看出,对于裁剪参数,DAPO同时引入了「低裁剪」ε_{low}和「高裁剪」ε_{high}两个界限。 这是因为: 高裁剪限制模型的探索能力,避免模型过度增加低概率token的概率,从而控制生成多样性; 低裁剪确保高概率token的概率不会骤降,保持模型输出的稳定性。 低概率token的更新空间远小于高概率token。 此外,DAPO的实验中发现,被裁剪的token的最大输出概率通常小于0.2。 这也证明了高裁剪限制了低概率token概率的提升,进而抑制了模型的多样性。如图2所示: 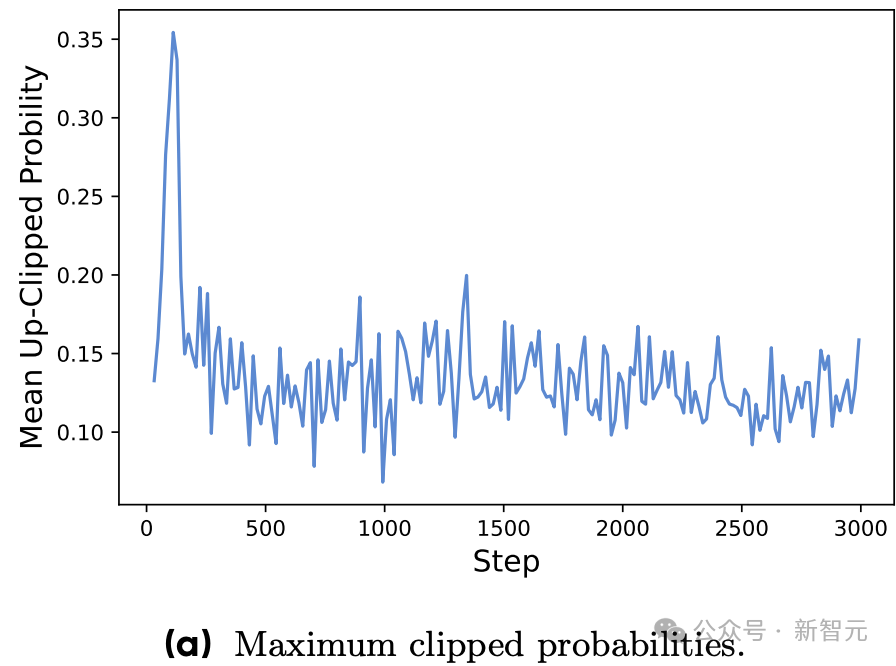 图2:最大裁剪概率 高低双裁剪的策略如下: ε_{low}:用于限制高概率token概率的下降,防止其概率骤减,通常设置得较小; ε_{high}:用于限制低概率token概率的增加,允许更多探索空间,通常设置得较大。 在DAPO中,有ε_{low} 当A>0(即奖励为正)时,裁剪上限为(1+ε_{high}),较大的ε_{high}可避免低概率token被过早裁剪,允许其更新; 当A(即奖励为负)时,裁剪下限为(1−ε_{high}),适当限制高概率token的更新速度,避免其概率下降过快。 动态采样 在当前强化学习算法中,同一个prompt需要采样多次形成一个group。 如果该组内所有采样结果的正确率都是1(即奖励全为正)或全为0(即奖励全为负),那么该组的优势值\hat{A}为0,导致无法产生有效的梯度更新,降低了样本效率。 如下图3所示,随着训练进行,有效样本在batch中的占比逐渐下降: 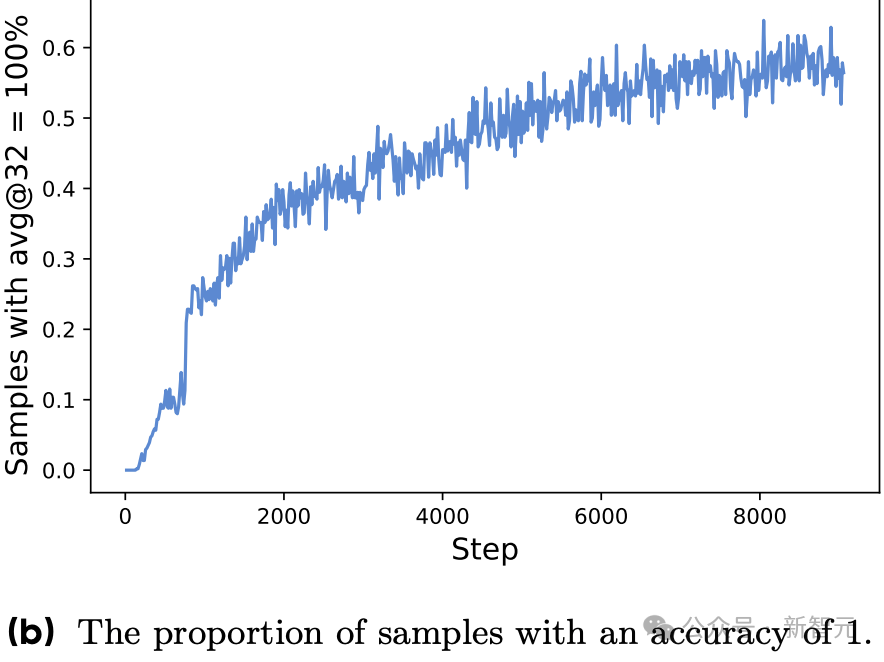 图3:准确率为1的样本比例 为了解决这个问题,DAPO引入了动态采样机制: 在训练前,过滤掉奖励全为0或全为1的group; 保证每个batch中的样本都能产生有效梯度,同时维持batch的大小一致; 随着训练步数增加,模型准确率提高,被过滤的样本也随之增多,因此虽然训练速度不一定加快,但样本效率更高,有助于模型更快收敛。 Token级策略梯度损失 在原始的GRPO中,损失是基于样本整体计算的。这种做法可能导致长文本中的token学习效果较差。 例如: 长输出样本的token损失为: 短输出样本的token损失为: 计算总损失L_{long}+L_{short}时,虽然平均了,但因为N₁>N₂,导致长样本的学习权重被稀释。 此外,实验也发现长内容容易生成无意义token,应该给予更多关注。 因此DAPO将损失改为每个token直接参与计算,总损失形式如下: 上述例子中的损失形式也相应变为: 过长奖励重塑 在大语言模型(LLMs)训练中,通常会设置max_token限制生成长度,超过这个长度的样本会被截断。 如果对这些截断样本的奖励设计不合理,可能会引入奖励噪声,干扰训练。 过去的方法通常会对这些样本进行惩罚,但这可能导致本应合理的长答案被错误惩罚。 为此,DAPO引入了惩罚过渡区间,其奖励设计如下: 设定L_{cache}为缓冲区; L_{max}为最大长度; |y|为当前生成文本的长度。 当∣y∣+Lcache≤Lmax时,文本长度小于最大允许长度max_token,因此不施加惩罚。 当∣y∣+Lcache>Lmax且∣y∣ 当∣y∣≥Lmax时,施加最大惩罚。 图4展示了在基准设置下,使用动态采样前后的训练进度变化。 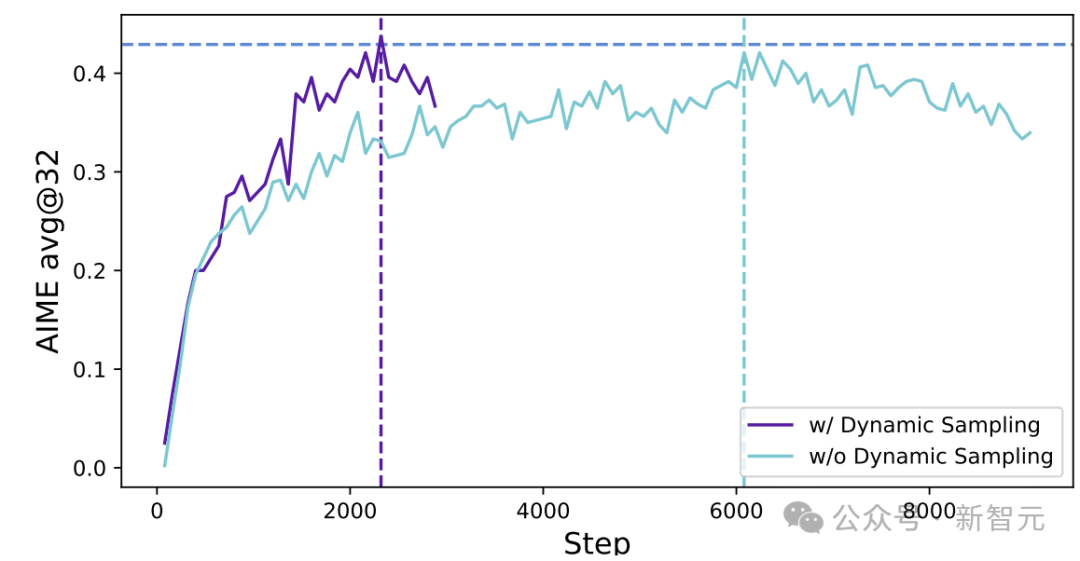 图4:在基准设置下,应用动态采样前后的训练进度对比 |
|